MySQL 索引
能说说什么是索引吗?索引的种类有哪些?
- 索引 (index) 是帮助数据库高效获取数据的数据结构
- 索引是在基于数据库表创建的,它包含一个表中某些列的值以及记录对应的地址,并且把这些值存储在一个数据结构中
- 最常见的就是使用哈希表、B+ 树作为索引,项目中我们使用 lnnoDB 引擎,默认的是 B+ 树
什么情况下适合建索引?
- 一般来说,在 WHERE 和 JOIN 中出现的列需要建立索引,因为 MySQL 只对
<、<=、=、>、>=、BETWEEN、IN以及某些时候的 LIKE 才会使用索引 (以通配符 % 和 _ 开头作查询时,MySQL不会使用索引) - 通常会根据慢查询日志来优化 SQL 以及判断是否建索引
你们在创建索引的时候会考虑哪些因素呢?
- 在日常工作中,我们会通过开慢查询去记录一些执行时间比较久的 SQL 语句,我们公司慢查询阈值是500ms,找出这些 SQL 语句后,我们用到 explain 命令来查看这些 SQL 语句的执行计划
- 查看该SQL语句有没有使用上索引,有没有做全表扫描,把查询条件中没有建立索引的列创建索引
在创建联合索引时,你是怎么考虑多个字段之间的顺序的?
- 在创建多列索引时,我们根据业务需求,where 子句中使用最频繁的一列放在最左边,因为MySQL索引查询会遵循最左前缀匹配的原则,即最左优先,在检索数据时从联合索引1的最左边开始匹配
- 所以当我们创建个联合索引的时候,如 (key1,key2,key3),相当于创建了 (key1)、(key1,key2) 和 (key1,key2,key3) 三个索引,这就是最左匹配原则
MySQL 为什么使用 B+ 树?
- 由于索引是存在于磁盘中,当索引非常大的时候,比如达到几个G的时候,无法一次加载到内存中,所以数据库中索引使用的是查找效率更高的树形结构
- B+ 树是平衡多路查找树,是为磁盘等外存储设备设计的一种平衡查找树
- 系统从磁盘读取数据到内存时是以磁盘块 (block) 为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,InnoDB 存储引擎中有页 (Page) 的概念,页是其磁盘管理的最小单位
- InnoDB存储引擎中默认每个页的大小为 16KB,可通过参数 innodb_page_size 设置页的大小,InnoDB 在把磁盘数据读入到磁盘时会以页为基本单位,在查询数据时,如果一个页中的每条数据都能有助与定位数据记录的位置,这将会减少磁盘 IO 次数,提高查询效率
- B+ 树使用有序数组链表 + 平衡多叉树改良了 B 树的有序数组+平衡多叉树
- B+ 树的关键字全部存放在叶子节点中,非叶子节点用来做索引,而叶子节点中有一个指针指向一下个叶子节点,做这个优化的目的是为了提高区间访问的性能
- 数据库索引采用 B+ 树的主要原因是 B 树在提高了磁盘 IO 性能的同时并没有解决元素遍历效率低下的问题,正是为了解决这个问题,B+ 树应运而生,B+ 树只要遍历叶子节点就可以实现整棵树的遍历,而且在数据库中基于范围的查询是非常频繁的,也是 B+ 树的优势所在
- 例如:要查 5-10之间的数据,B+ 树一把到 5 这个标记,再一把到10,然后串起来就行了,而 B 树在找到第一个符合条件的数字 5 后,访问完第一个关键字所在的块后得遍历这个 B 树,获取下一个块,直到遇到一个不符合条件的关键字,遍历的过程是比较复杂的
和 Hash 索引比较起来有什么优缺点吗
- 哈希索引适合等值查询,但是无法进行范围查询
- 哈希索引没办法利用索引完成排序
- 哈希索引不支持多列联合索引的最左匹配规则;如果有大量重复键值的情况下,哈希索引的效率会很低,可能存在哈希碰撞问题
B+ 树的叶子节点都可以存储哪些东西
- InnoDB 的 B+ 树可能存储的是整行数据,也有可能是主键的值
- 索引 B+ 树的叶子节点存储了整行数据的是主键索引,也被称之为聚簇索引
- 索引 B+ 树的叶子节点存储了主键的值的是非主键索引,也被称之为非聚簇索引
聚簇索引和非聚簇索引,在查询数据的时候有区别吗
- 主键索引查询只会查一次,而非主键素引需要回表查询多次,通过覆盖索引也可以只查询一次,覆盖索引指一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取
- MysQL 只需要通过索引就可以返回查询所需要的数据,这样避免了查到索引后再返回表操作,减少 IO 提高效率
- 聚簇索引:以 InnoDB 作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键
- 非聚簇索引:以主键以外的列值作为键值构建的 B+ 树索引,我们称之为非聚簇索引
什么是覆盖索引
- 解释一: 就是 select 的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖
- 解释二: 索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了,如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引
- 解释三:是非聚集组合索引的一种形式,它包括在查询里的 Select、Join 和 Where 子句用到的所有列(即建立索引的字段正好是覆盖查询语句 [select子句] 与查询条件 [Where子句] 中所涉及的字段,也即,索引包含了查询正在查找的所有数据)
- 不是所有类型的索引都可以成为覆盖索引,覆盖索引必须要存储索引的列,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引
- 当发起一个被索引覆盖的查询(也叫作索引覆盖查询)时,在EXPLAIN的Extra列可以看到“Using index”的信息
如果每天几百万,一个月就是几千万,有没有优化手段
- 中间件选型
- Cobar
- TDDL
- Atlas
- Sharding-jdbc
- MyCat
- 分片键和分片规则
- 如何避免所有库扫描
- 分布式全局唯一ID
- 跨库 Join
- 跨库事务问题
- 跨库排序分页问题
- 数据迁移、扩容问题
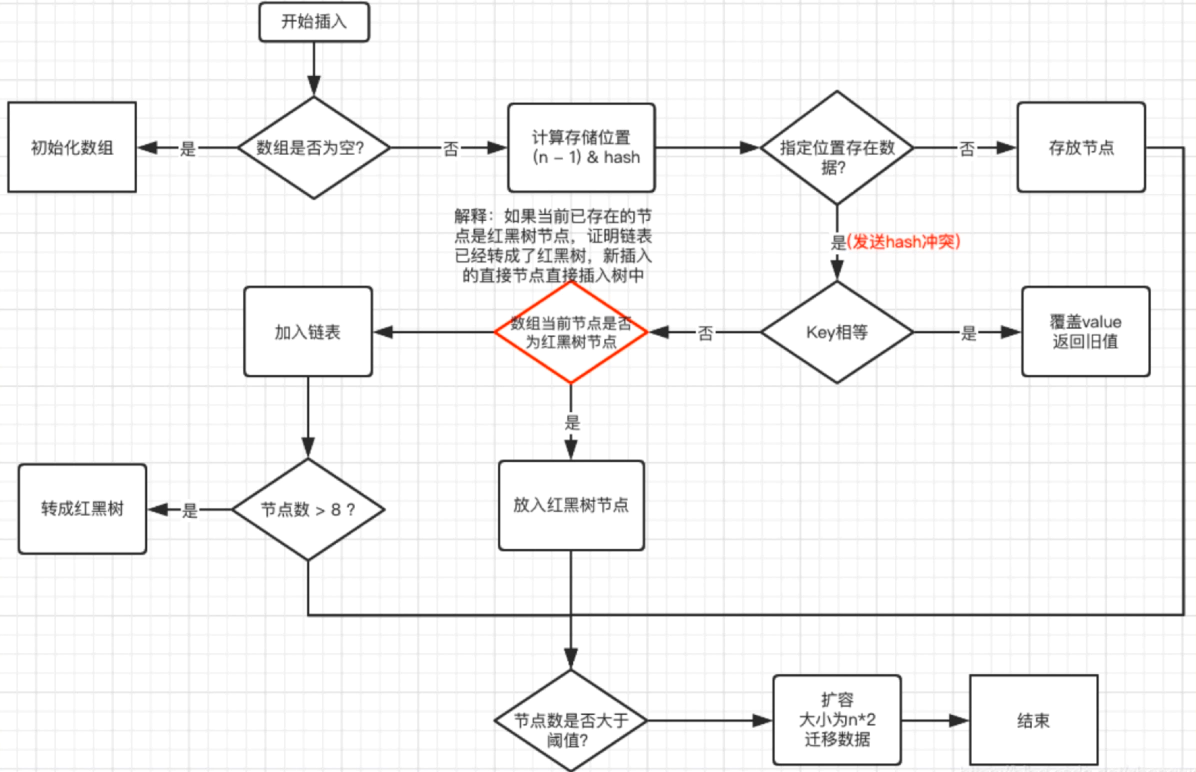
HashMap
说一说 Hashmap 理解
- JDK8 之前:数组 + 链表
- JDK8 之后:数组 + 链表 + 红黑树
HashMap 如何设定初始容量
- 一般如果 new HashMap() 不传值,默认大小是16,负载因子是0.75
- 如果自己传入初始大小 k,初始化大小为大于 k 的 2 的整数次方,例如如果传 10,大小为 16
HashMap 的哈希函数是怎么设计的
hash 函数是先拿到 key 的 hashcode,是一个 32 位的 int 值,然后让 hashcode 的高16 位和低 16 位进行异或操作
1.8 对 HashMap 的优化
- 在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成后再判断是否需要扩容
- 1.7扩容的时候需要对原数组的元素进行重新 hash 定位在新数组的位置,1.8 采用更简单的判断逻辑,位置不变或索引 + 旧容量大小
- 链表的插入方式从头插法改成了尾插法,简单说就是插入时,如果数组位置上已经有元素,1.7将新元素放到数组中,原始节点作为新节点的后继节点,1.8遍历链表将元素放置到链表的最后
- 数组 + 链表改成了数组 + 链表 + 红黑树
HashMap 是线程安全的吗
- Java中有 HashTable、Collections.synchronizedMap、以及 ConcurrentHashMap 可以实现线程安全的Map
- HashTable是直接在操作方法上加 synchronized 关键字,锁住整个数组,粒度比较大
- Collections.synchronizedMap 是使用 Collections 集合工具的内部类,通过传入Map封装出一个SynchronizedMap对象,内部定义了一个对象锁,方法内通过对象锁实现
- ConcurrentHashMap使用分段锁,降低了锁粒度,让并发度大大提高
1.7 与 1.8 的 ConcurrentHashMap 实现有什么不同吗
- 1.7:ReentrantLock + segment + hashentry
- 1.8:数组 + 链表 + 红黑树 + CAS
JVM
什么情况下会发生栈内存溢出
JVM 内存模型
JVM 一次完整的 GC 过程
垃圾回收算法
- 标记清除
- 标记整理
- 复制
- 分代收集
如何判断对象是否存活
有哪几种垃圾回收器,有哪些优缺点
CMS 垃圾回收器特点
- CMS 以获取最小停顿时间为目的
- 在一些对响应时间有很高要求的应用或网站中,用户不能有长时间的停顿,CMS 可以用于此场景
- CMS 执行过程分为:初始标记(STW)、并发标记、并发预清理、冲标记(STW)、并发清理、重置
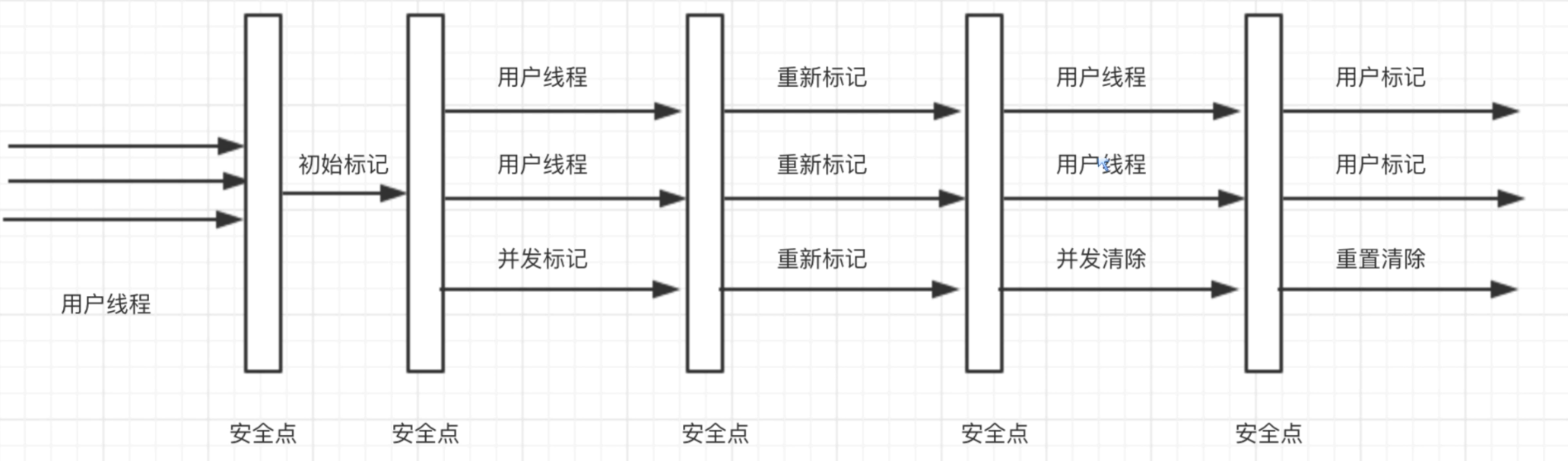
说一说对 G1 的了解
什么是类加载,类加载过程是什么样的
Netty
BIO、NIO、AIO
- BIO:同步阻塞IO
- NIO:同步非阻塞
- AIO:异步非阻塞
NIO 开发流程
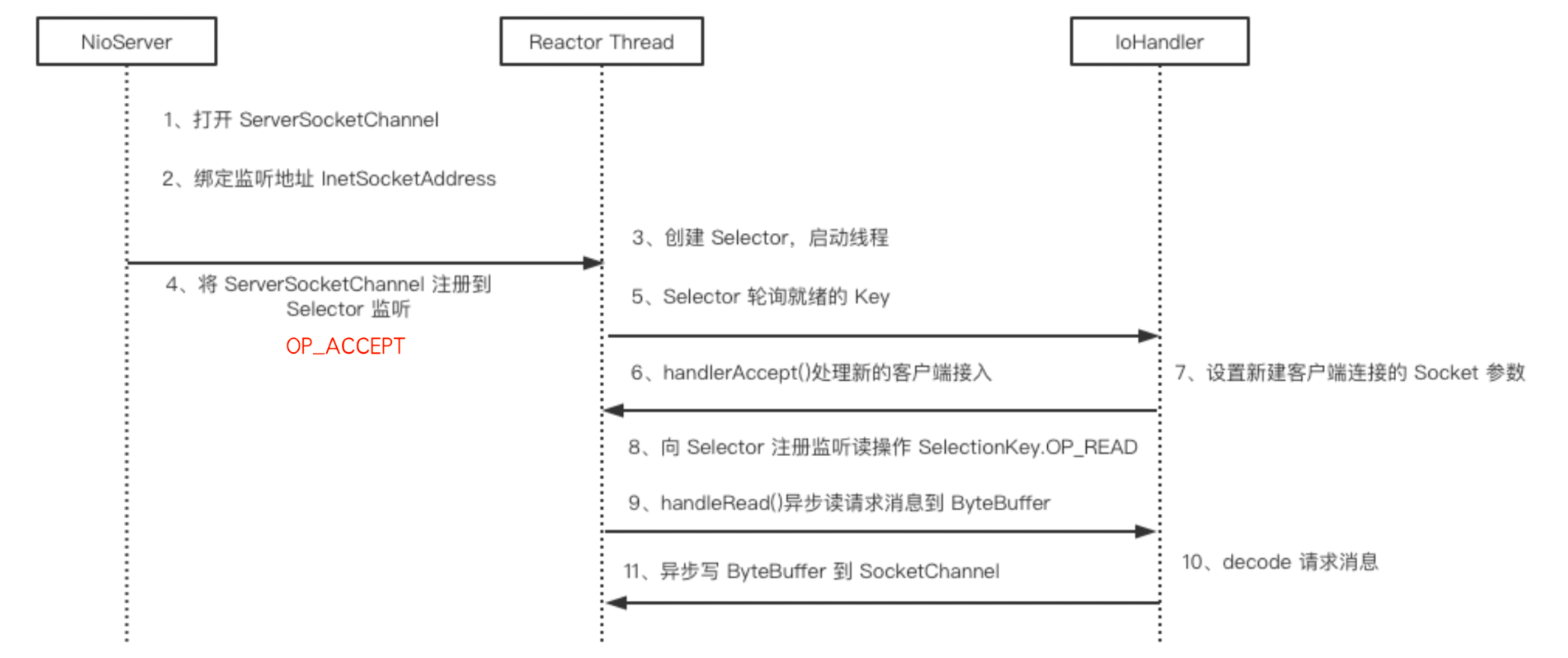
Netty 开发流程
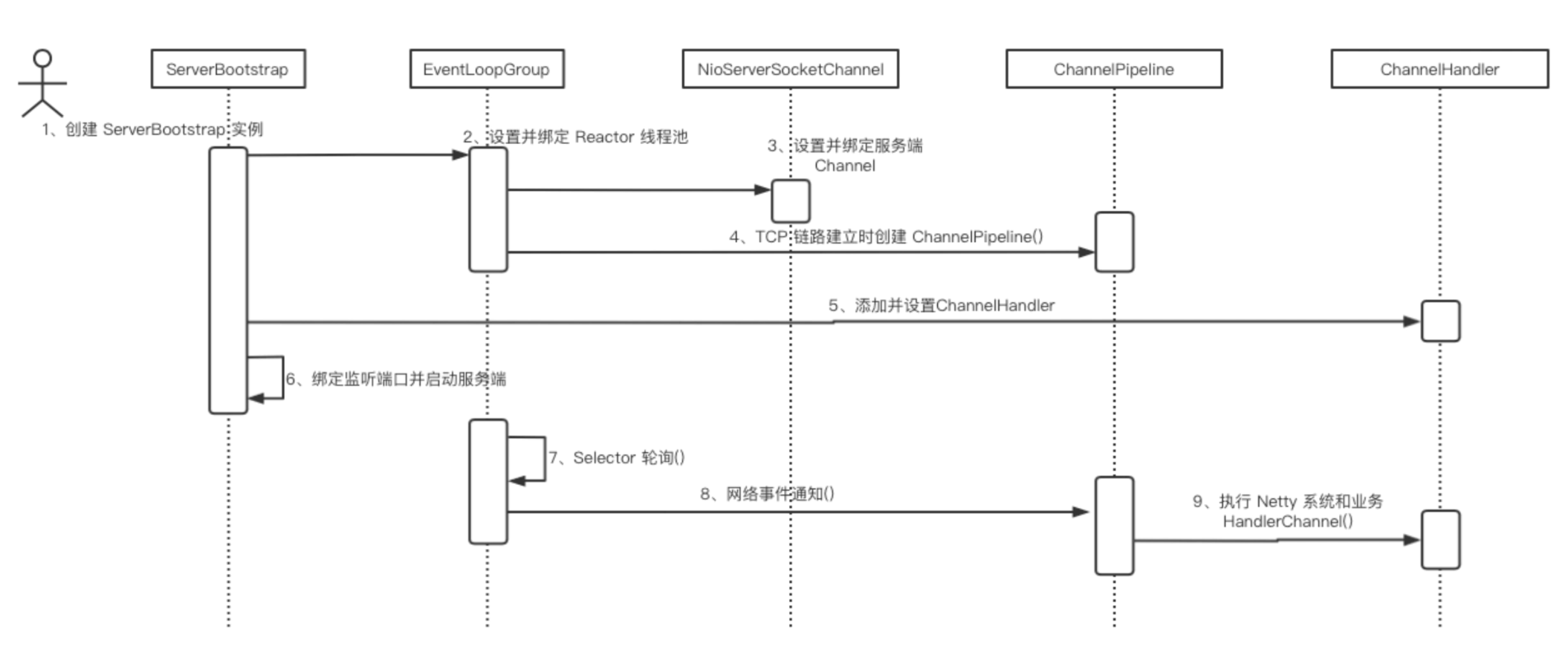
Netty 服务端线程模型
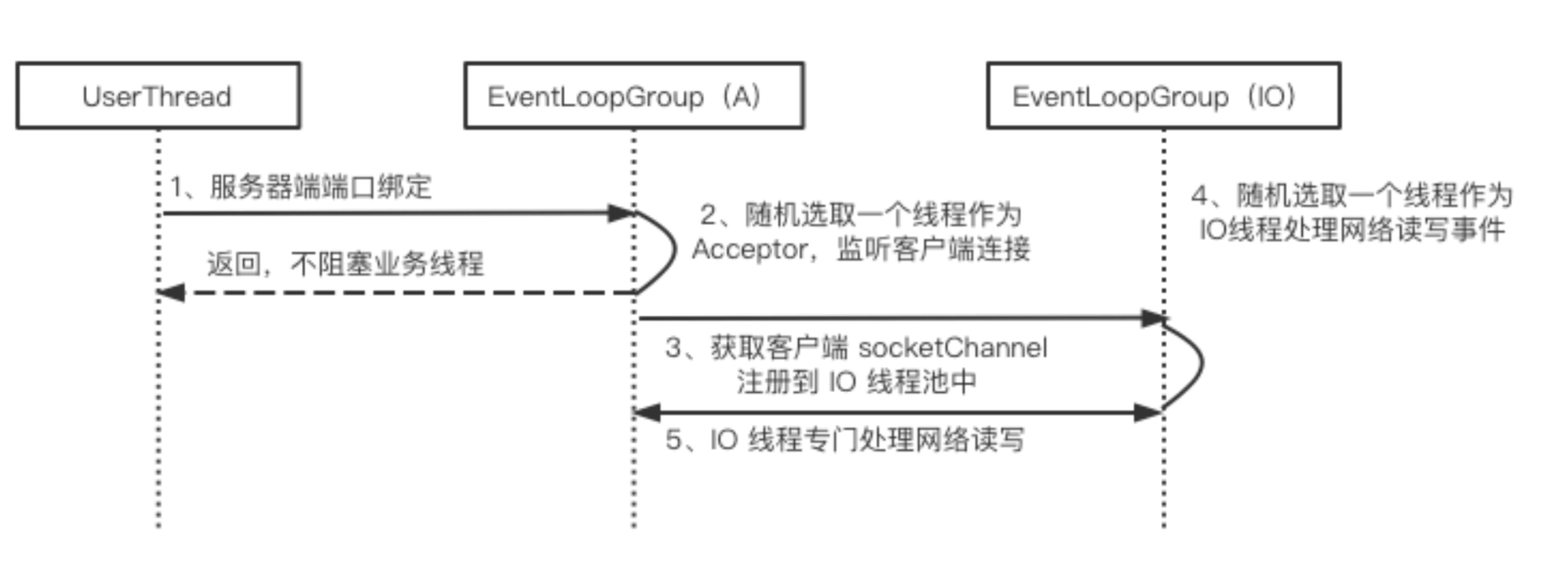
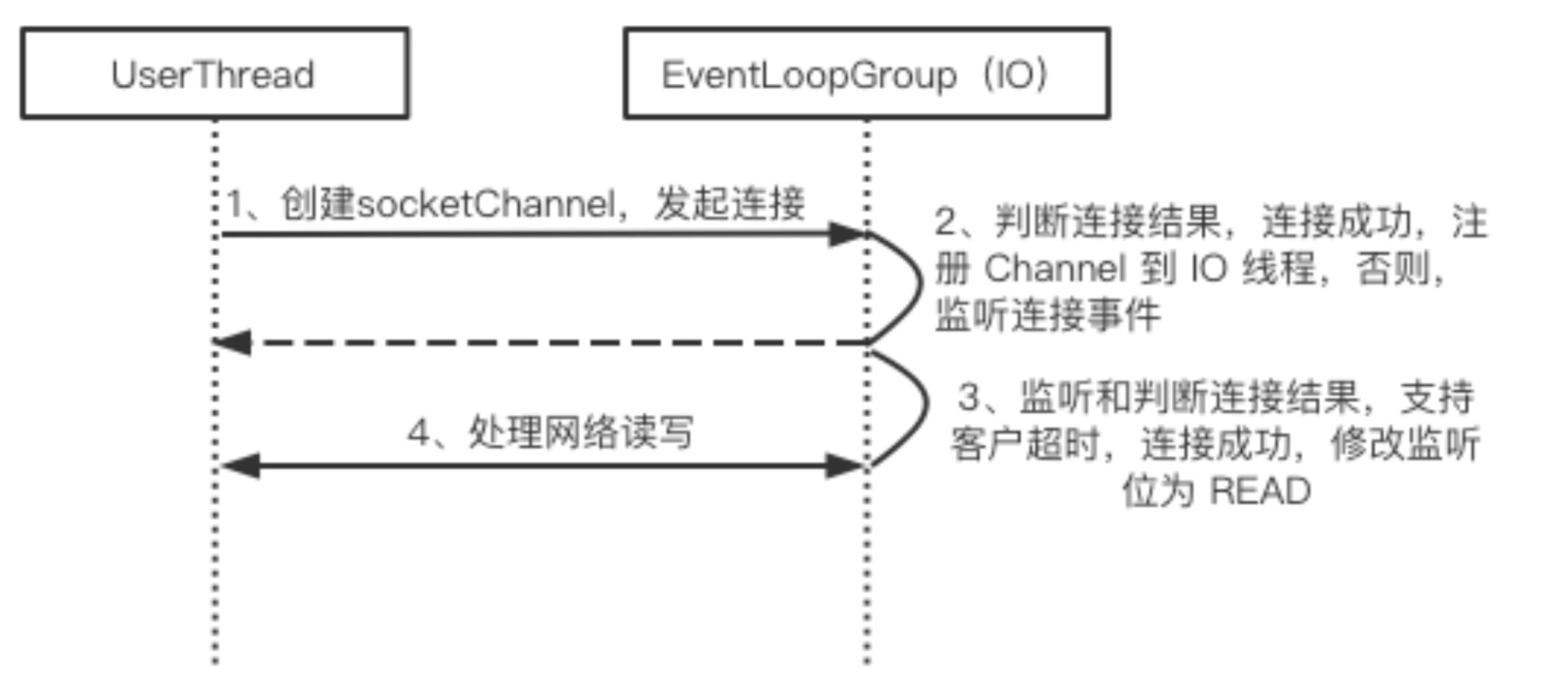
Netty 客户端线程模型